-
DirectX Chapter2 행렬 대수코오딩/DirectX, 다렉엑 2026. 1. 11. 19:20반응형
DirectX 12를 이용한 3D 게임 프로그래밍 입문 2
DirectX를 공부하며 궁금한 점을 작성하였습니다.
Chapter02 Keyword
01 행렬의 곱
𝐶𝑖𝑗 = (A의 i번째 행벡터 ) ⋅ ( B의 j번째 열벡터 )- A의 열의 개수 = B의 행의 개수
- A의 "열 벡터 차원" = B의 "행 벡터 차원"
02 Linear Combination, 선형 결합In Direct X
𝑢 = 1 × 𝑛 (1×n 행벡터) 𝐴 = 𝑛 × 𝑚 (n×m 행렬) 이면 𝑢𝐴선형 결합은 일차행렬과 결합한것.
DirectX는 Row Vector(행 벡터) 규칙! !
- 배열 접근이 직관적
- 구조체 기반 수치 연산 structure Vector {x,y,z}- C스타일 API
- CPU 메모리 접근패턴, HLSL 문법이 행벡터 기준이므로
In Houdini
vector p = {1,2,3}; matrix M = maketransform(...); p = M * p;houdini에서의 Matrix의 곱은 Matrix * vector여야했음.
Houdini / VEX는 Column Vector(열 벡터) 규칙 ! !
- 행렬 곱 순서가 논리적으로 읽기 쉬워서
- 좌표 변환이 핵심인 Geometry 처리!
- 좌표 변환을 왼쪽에서 적용, 수학 교과서 표기와 동일@P = M*@P;Quaternion으로 Object 돌렸을때도 선형 결합 이런식으로 활용했었음
03 행렬
(x,y,z)⇒(x,y,z,1)Houdini에서는 4x4 정사각 행렬만 활용했지만,
- 전부 공간 변환만을 활용
DirectX는 단순히 "Geometry Transform tool"이 아닌,
-Render Pipeline-Shader compute
- light 등등
비정사각 행렬도 활용.04-1 소행렬, 여인수, 딸린 행렬
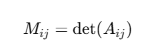
소행렬
- A𝑖𝑗 = 행렬 A에서 i행, j열을 제거한 행렬
-소행렬 : 제거한 행렬
행렬식 구하는 식
- 정방행렬 -> 실수값 출력
e.g) 2차 행렬식 : ad-bc
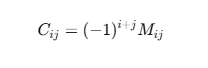
여인수(Cofactor)
-> 소행렬에 부호를 붙힌것
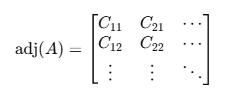
딸린 행렬
- 여인수들을 전치해서 만든 행렬
04-1딸린행렬을 만들기 위한 순서
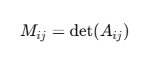


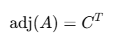
[A의 딸린 행렬을 만드는 절차]
01. A의 소행렬 M𝑖𝑗 계산
02. 여인수(𝐶𝑖𝑗) 계산
03. 여인수 행렬C 구성
04. 여인수 행렬C 전치 ->adj(A)
- 이 모든 딸린 행렬을 만드는건 역행렬을 위함 구하기 위함이었다?
05 역행렬
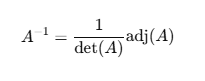
역행렬
- 역행렬은 정방향행렬에만 있다

- A랑 차원이 높아져서 그렇지 고등학교 수학때 배웠던 역행렬 구하는 공식이네
4x4행렬보다 더 큰 행렬에는 가우스 소거법이 쓰인다.
3D graphics에서 주로 다루는 행렬은 추후 역행렬 공식을 미리 알 수있는 특별한 형태가 있다?06 행렬 형식들
XMVECTOR 인스턴스에는 반스디 XMVECTORF32형식을 사용!
explict XMMATRIX(_In_reads_(16) const float *pArray); // const float* pArray 와 같은 동작06-01 explict를 활용할때의 이점?
float[16]배열임을 알려줌, XMMATRIX의 자동 변환을 막는다.
06-02 _in_reads_(16)이란?
MSCV 전용 SAL annotation : 최소 float 16개를 읽는 포인터
FXMVECTOR 첫 번째 벡터 인자 CXMVECTOR 세 번째 벡터 인자 FXMMATRIX 첫 번째 행렬 인자 DirectXMath 문서화는 행렬을 클래스 자료 멤버에 저장할때, XMFLOAT4x4형식 사용 추천한다.
//XMFLOAT4x4 -> XMMATRIX inline XMMATRIX XM_CALLCONV XMLoadFloat4x4(const XMFLOAT4X4* pSource); //XMMATRIX -> XMFLOAT4x4 inline void XM_CALLCONV XMStoreFloat4x4(XMFLOAT4X4* pDestination, FXMMATRIX M);구분 XMMATRIX XMFLOAT4x4 용도 연산용 저장용 내부 XMVECTOR 4개 (SIMD) float 16개 정렬 16바이트 정렬 필요 정렬 필요 없음 크기 64바이트 64바이트 안전성 멤버 변수로 쓰기 위험 멤버 변수로 안전 캐시/메모리 SIMD 친화적 일반 메모리 친화적 08 Calling Convention 호출 규약
C/C++ 에서 함수 호출시, 인자 전달, 리턴 방식을 정의한 규칙
- 어떤 레지스터에 넣을지?- 스택에 쌓을지?
- 반환 값은 어디서 받을래?
Compiler와 CPU가 약속해야 함수 호출이 올바르게 작동함
01 __fastcall
[특징]
최초 두 개 정수 이자를 ECX, EDX 레지스터로 전달.
나머지는 스택을 통한 전달
반환값은 EAX(정수)로
[목적]
- 스택 접근 최소화 : 속도 향상
- 작은 함수 / 많이 호출 되는 함수 최적화int __fastcall Add(int a, int b) { return a + b; }a(첫번째 인자) ->ECX
b(두번째 인자)-> EDX
return EAX
" __fastcall 규약"
02 __vectorcall
:SIMD vector 최적화 호출 규약
DirectXMath에서 XMVECTOR 같은 SIMD 벡터를 매개변수로 전달할 때 사용.[특징]
1. XMVECTOR /Float4 같은 SIMD 타입을 XMM 레지스터로 전달
2. 일반 정수 / 포인터는 레지스터(EAX, ECX, EDX 등)
3. 반환 값도 XMM레지스터
4. 스택 사용 최소화[목적]
- SIMD 연산 최적화 -> 레지스터에서 바로 연산
- 복사/로드 비용 제거 ->속도 크게 향상
XMVECTOR __vectorcall Add(XMVECTOR a, XMVECTOR b){ return a+b; }a, b->XMM0, XMM1
- return ->XMM0
- 스택 접근 없음 : 매우 빠름
++ DirectXMath 특징
" DirectXMath 목표: SIMD 연산을 레지스터에서 바로 수행"
01 XMMATRIX형식의 인수를 받는 생성자는 항상 CXMMATRIX를 사용하라!
=> 그냥 cosnt XMMATRIX&로 매개변수를 하면, 스택에있는 XMMATRIX를 참조하면서 내부연산시 레지스터로 복사가 필요함!
CXMMATRIX는 XMM레지스터로 직접 전달한다. :-> 연산 최적화
02 생성자에는 XM_CALLCONV 호출 규약 지시자를 사용하지 말아야한다
XM_CALLCONV는 보통 __vectorcall 호출규약
함수 호출시 레지스터 전달 규칙을 바꾸는 지시자!
class Foo { XMMATRIX m; public: Foo(CXMMATRIX M); // ✅ 안전 };class Foo { XMMATRIX m; public: Foo(XM_CALLCONV CXMMATRIX M); // ❌ 위험생성자도 특별한 함수이기에,
생성자는 항상 this 포인터를 첫번째 인자로 숨겨서 전달.
호출 규약을 바꾸면 this 전달 방식과 충돌 가능struct XMMXATRIX{ XMMATRIX(CXMMATRIX M); //생성자에는 호출 규약 지시자 x } XMMATRIX XM_CALLCONV operator*(FXMMATRIX M);연산 함수에서만 XM_CALLCONV 적용 가능!
생성자는 this 포인터 전달, 호출 규약이 복합적으로 얽혀있어서,
XM_CALLCONV 같은 SIMD 최적화 호출 규약을 사용하면 ABI 충돌과 예기치 못한 동작이 발생할 수있다.
생성자에서는 그냥 CXMMATRIX 타입만 쓰고 호출 규약 지시자는 제거!09 CPU 레지스터
CPU가 연산할때 가장 빠른 임시 저장공간
- RAM보다 (10배 ~ 100배)빠름
- 메모리를 읽고 쓰는 대신 레지스터 안에서 직접 연산.
레지스터 용도 EAX Accumulator (연산 결과, 함수 반환) ECX Counter (루프, __fastcall 인자 전달) EDX Data / I/O (보조 계산, __fastcall 인자 전달) XMM 레지스터?
- SSE/SIMD 연산용 레지스터
- 레지스터 안에서 벡터 연산을 직접 수행 : RAM 접근 최소화#include <Windows.h> #include <DirectXMath.h> #include <DirectXPackedVector.h> #include <iostream> using namespace std; using namespace DirectX; using namespace DirectX::PackedVector; ostream& XM_CALLCONV operator << (ostream& os, FXMVECTOR v) { XMFLOAT4 dest; XMStoreFloat4(&dest, v); os << "(" << dest.x << ", " << dest.y << ", " << dest.z << ", " << dest.w << ")"; return os; } ostream& XM_CALLCONV operator <<(ostream& os, FXMMATRIX m) { for (int i = 0; i < 4; i++) { os << XMVectorGetX(m.r[i]) << "\t"; os << XMVectorGetY(m.r[i]) << "\t"; os << XMVectorGetZ(m.r[i]) << "\t"; os << XMVectorGetW(m.r[i]); os << endl; } return os; } int main() { if (!XMVerifyCPUSupport()) { cout << "DirectXMath를 지원치 않어!" << endl; return 0; } XMMATRIX A( 1.0f, 0.0f, 0.0f, 0.0f, 0.0f, 2.0f, 0.0f, 0.0f, 0.0f, 0.0f, 4.0f, 0.0f, 1.0f, 2.0f, 3.0f, 1.0f); XMMATRIX B = XMMatrixIdentity(); XMMATRIX C = A * B; XMMATRIX D = XMMatrixTranspose(A); XMVECTOR det = XMMatrixDeterminant(A); XMMATRIX E = XMMatrixInverse(&det, A); XMMATRIX F = A * E; cout << "A = " << endl << A << endl; cout << "B = " << endl << B << endl; cout << "C = " << endl << C << endl; cout << "D = " << endl << D << endl; cout << "determinant(A) = " << det << endl << endl; cout << "E = inverse(A) = " << endl << E << endl; cout << "F = A*E = " << endl << F << endl; return 0; }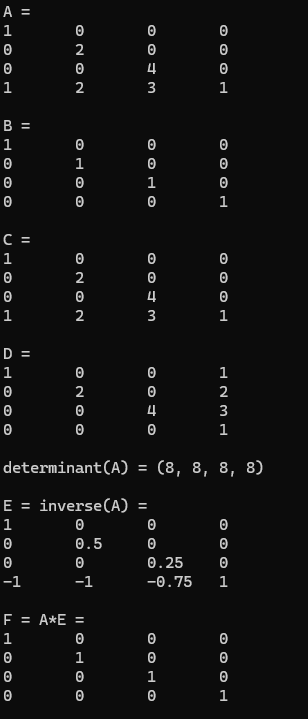

남만 알고 있는 쓰리디에 대한 정보를
속이 쓰리지 않게,
소기쓰리디반응형'코오딩 > DirectX, 다렉엑' 카테고리의 다른 글
DirectX Chapter3 변환 (0) 2026.01.13 DirectX Chapter1 벡터 대수 (0) 2026.01.10